- Deutsch
-
EnglishDeutschItaliaFrançais日本語한국의русскийSvenskaNederlandespañolPortuguêspolskiSuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикAfrikaansIsiXhosaisiZululietuviųMaoriKongeriketМонголулсO'zbekTiếng ViệtहिंदीاردوKurdîCatalàBosnaEuskeraالعربيةفارسیCorsaChicheŵaעִבְרִיתLatviešuHausaБеларусьአማርኛRepublika e ShqipërisëEesti Vabariikíslenskaမြန်မာМакедонскиLëtzebuergeschსაქართველოCambodiaPilipinoAzərbaycanພາສາລາວবাংলা ভাষারپښتوmalaɡasʲКыргыз тилиAyitiҚазақшаSamoaසිංහලภาษาไทยУкраїнаKiswahiliCрпскиGalegoनेपालीSesothoТоҷикӣTürk diliગુજરાતીಕನ್ನಡkannaḍaमराठी
Server und ihre gemeinsamen Fehler verstehen
- 2024/12/29
- 33
Katalog

Einführung in Server
Ein Server ist ein leistungsstarker Computer, der für Hochgeschwindigkeits-Computing und Datenverarbeitung ausgelegt ist.Im Gegensatz zu PCs (PCs) werden Server für eine höhere Leistung erstellt, können größere Workloads verwalten und sind im Allgemeinen teurer.Ihre Hauptfunktion besteht darin, Rechenressourcen oder Anwendungsdienste für Clients innerhalb eines Netzwerks bereitzustellen.Diese Kunden reichen von Geräten wie PCs und Smartphones bis hin zu speziellen Systemen wie Geldautomaten oder großen Vorgängen wie Zugsteuerungsnetzen.Die Server sind aufgrund ihres Hochgeschwindigkeits-CPUs, des zuverlässigen Langzeitbetriebs, der E/O-Funktionen (Effizienz-/Ausgangs) und einer hervorragenden Skalierbarkeit hervorragend.Diese Merkmale machen sie in Umgebungen, in denen eine konsistente und effiziente Servicebereitstellung von entscheidender Bedeutung ist, wesentlich.
Funktionell konzentrieren sich die Server auf drei wichtige Aufgaben: Beantwortung von Serviceanfragen, effizientes Bearbeiten von Aufgaben und die Gewährleistung einer kontinuierlichen Zuverlässigkeit.Während ihr internes Design fortgeschritten ist, teilen die Server Kernkomponenten mit Standard -PCs, einschließlich einer zentralen Verarbeitungseinheit (CPU), Festplatte, Speicher, Betriebssystem und Systembus.Diese Komponenten sind jedoch optimiert, um die einzigartigen Anforderungen von Servervorgängen zu erfüllen und die reibungslose Integration und die zuverlässige Leistung in verschiedenen vernetzten Systemen sicherzustellen.
Wie unterscheiden sich Server von PCs?

Abbildung 2. PC vs. Server
PCs (PCs) sind für den individuellen Gebrauch mit begrenztem Betriebsbereich und Auswirkungen ausgelegt.Andererseits werden Server so konstruiert, dass sie mehrere Benutzer und Systeme gleichzeitig bedienen.Ein Serverausfall kann ganze Netzwerke stören.Im Gegensatz zu PCs, die die persönliche Produktivität priorisieren, werden die Server für Hochleistungsaufgaben in viel größerem Maßstab entwickelt.Die Server erfüllen strenge Anforderungen für die Verarbeitungsleistung, die E/A -Leistung, die Zuverlässigkeit und die Skalierbarkeit, um sicherzustellen, dass sie ohne Versagen kontinuierliche und starke Workloads verarbeiten können.
Obwohl Server und PCs ähnliche grundlegende Komponenten wie CPUs, Speicher und Speicher haben - sind die Designs und die Spezifikationen von Serverkomponenten weitaus weiter erweitert.Server sind für hohe Arbeitsbelastungen, langfristige Zuverlässigkeit und effizientes Ressourcenmanagement optimiert.Im Folgenden finden Sie einen Vergleich, der diese Unterschiede unter Verwendung des R5300G4X -Servers als Beispiel unter Verwendung des R5300G4X -Servers hervorhebt:
|
Komponenten |
PC |
Server (R5300G4X -Beispiel) |
|
Chassis |
Unterschiedliche Formen, typischerweise vertikal |
Standard flaches Design, gemessen in Höheneinheiten (u), z. B. 2U
Server.Racks können mehrere Server unterbringen. |
|
Hauptplatine |
Verbraucherqualität, begrenzte Funktionalität |
Professionelles Design mit Funktionen für Skalierbarkeit,
Zuverlässigkeit und Hochgeschwindigkeitsvorgänge. |
|
CPU |
1 Prozessor |
Unterstützt bis zu 2 Intel® Xeon® der dritten Generation skalierbar
Prozessoren mit jeweils bis zu 40 Kernen. |
|
Erinnerung |
16 GB oder 32 GB |
Unterstützt bis zu 32 DDR4 -Module, mit Geschwindigkeiten von bis zu 3200 mT/s, und
ECC für die Fehlerkorrektur. |
|
Festplatte |
1–2 mechanische oder SSD -Laufwerke |
Bietet bis zu 41 2,5 "Festplattenschächte oder 20 3,5" Buchten + 4
2,5 "Buchten; unterstützt bis zu 28 NVME SSDs für die Hochgeschwindigkeitsspeicherung. |
|
E/A -Modul |
Nicht anwendbar |
Unterstützt bis zu 14 PCIE4.0 -Expansionsschlitze für Fortgeschrittene
Konnektivität und spezialisierte Add-Ons. |
|
Stromversorgung |
Einzelstromversorgung |
1+1 HOT-SWAPABLE-redundantes Netzteil, wodurch ununterbrochen gewährleistet ist
Vorgänge auch während der Wartung. |
|
Lüfter
|
1–2 Fans |
4 Gruppen hocheffizienter Fans mit N+1-Redundanz, die mit
Intelligente Kühlsysteme für ein optimales thermisches Management. |
|
Netzwerkkarte |
100 m oder 1000 m |
Ausgestattet mit 2 GE (Gigabit -Ethernet) -Anschließungen, um sicherzustellen
robuster Netzwerkdurchsatz. |
Server werden in Branchen verwendet, die eine hohe Zuverlässigkeit und Skalierbarkeit erfordern, wie Telekommunikations-, Finanz-, Spiel- und Internetdienste.Rechenzentren, in denen Hunderte oder Tausende von miteinander verbundenen Servern stattfinden, spielen eine entscheidende Rolle bei der Unterstützung dieser Branchen.Sie verwalten enorme Datenmengen und sorgen für eine nahtlose Bereitstellung von Diensten wie Finanztransaktionen, Netzwerkkonnektivität und Datenspeicherung an Millionen oder sogar Milliarden von Nutzern weltweit.
Was passiert, wenn der Server abstürzt?
Ein Serverabsturz kann schwerwiegende Konsequenzen haben und Dienste und Vorgänge stören, die davon abhängen.Da Server häufig eine große Anzahl von Benutzern unterstützen, kann ein Fehler weit verbreitete Störungen und erhebliche Verluste verursachen.
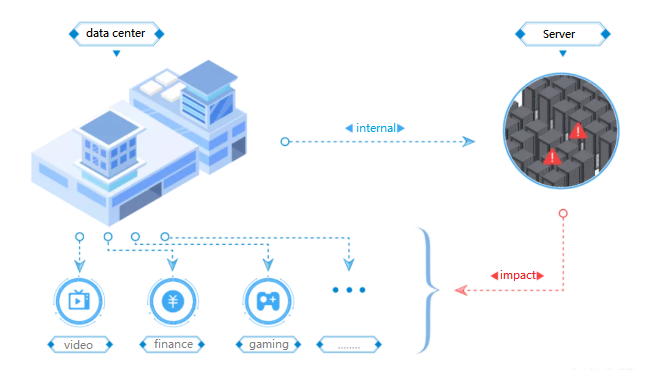
Abbildung 3.Die Auswirkungen eines Serverabsturzs
Auswirkungen auf Video -Streaming -Plattformen
In einer Video -Streaming -Plattform kann ein Serverabsturz Sie den Zugriff auf Videos haben und Frustration und Serviceausfälle verursachen.Für Inhaltsersteller sind die Einsätze sogar noch höher.Wenn Serverdaten verloren gehen, können Originalvideos, Animationen und andere kreative Arbeiten dauerhaft gelöscht werden.
Auswirkungen auf Finanzsysteme
Finanzsysteme verlassen sich stark auf stabile Server, um jede Sekunde Millionen von Transaktionen zu verarbeiten.Ein Serverabsturz kann Transaktionen einstellen, den Kapitalbörsen stören und zu erheblichen finanziellen Verlusten führen.Solche Vorfälle können Einzelpersonen, Unternehmen und sogar globale Märkte beeinflussen und die Serverzuverlässigkeit kritisch machen.
Auswirkungen auf wettbewerbsfähige Online -Spiele
Im Online-Spiel sind Server für die Echtzeit-Konnektivität von wesentlicher Bedeutung.Ein Absturz kann Millionen von Spielern gleichzeitig trennen, die Benutzererfahrung ruinieren und den Ruf des Spiels schädigen.Weit verbreitete Unterbrechungen führen häufig zu Frustration der Spieler, der öffentlichen Gegenreaktion und dem Umsatzverlust für das Unternehmen.
Die Bedeutung der Prävention
Serverabstürze in diesen Kontexten unterstreichen die wichtige Rolle von Servern bei der Aufrechterhaltung nahtloser Abläufe in allen Branchen.Um diese Risiken zu reduzieren, sind robuste Serverarchitektur, regelmäßige Wartung und zuverlässige Sicherungssysteme von wesentlicher Bedeutung.Diese Maßnahmen gewährleisten Überzeitungen, schützen Daten und minimieren Servicestörungen.
Warum stürzt der Server ab?
Server bilden die Grundlage für moderne digitale Operationen, die Leistung von Websites, Anwendungen und Diensten, die von Millionen verwendet werden.Trotz ihrer Robustheit können selbst die fortschrittlichsten Server Misserfolge erleben.Diese Ausfälle oder Abstürze beruhen häufig von begrenzten Ressourcen, der steigenden Nutzerbedarf oder unvorhergesehenen externen Faktoren.Nachfolgend finden Sie eine detaillierte Aufschlüsselung der Hauptgründe, die Server abstürzen und die Herausforderungen, die sie darstellen.
Die Lücke zwischen Benutzerwachstum und Serverleistung
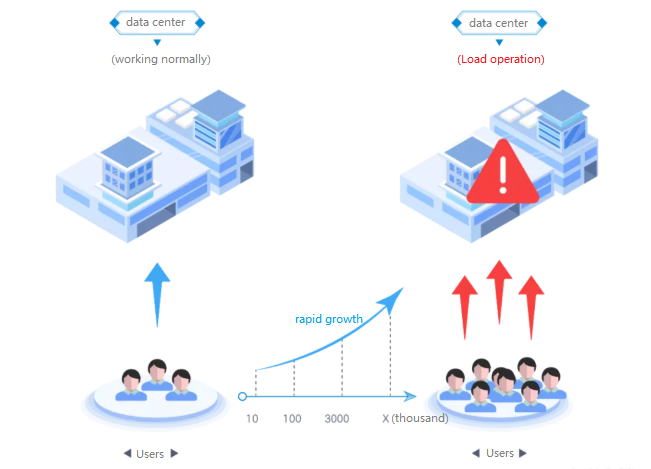
Abbildung 4. Auswirkung der Erhöhung der Benutzerbedarf auf Server
Wenn die Anzahl der Benutzer wächst, haben Server häufig Schwierigkeiten, die Leistung aufrechtzuerhalten.Rechenzentren mit Hunderten von Servern können zunächst große Benutzerbasis bewältigen, aber eine schnelle Erhöhung der Nachfrage kann diese Ressourcen schnell an ihre Grenzen bringen.Die Infrastruktur kann häufig nicht so schnell wie das Wachstum der Benutzeraktivität skalieren, insbesondere in unerwarteten Zeiträumen der exponentiellen Nachfrage.
Wenn die Benutzerzahlen beispielsweise innerhalb von Wochen doppelt oder dreifach verdreifacht werden, fehlen vorhandenen Servern häufig die Fähigkeit, Schritt zu halten.Dies führt zu langsameren Reaktionszeiten und einer verminderten Leistung.Skalierung der Infrastruktur - sei es durch Hinzufügen von Hardware oder Erstellung neuer Rechenzentren - erhebliche Zeit und Investition.Herkömmliche Methoden zur Erweiterung der Serverkapazität können zu langsam sein, um den sofortigen Anstieg anzugehen, so dass die Systeme während kritischer Zeiträume anfällig sind.
Ressourcenüberlastung von hohen Serviceanfragen
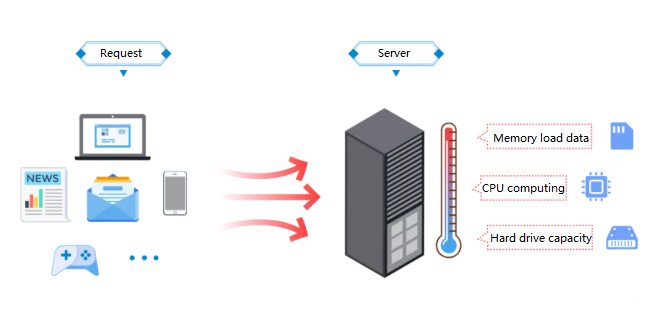
Abbildung 5. CPU, Speicher und Festplattenkapazität sind erschöpft
Server weisen Ressourcen wie CPU -Strom, Speicher und Speicher zu, um eingehende Anforderungen zu verarbeiten.Im Alter des Internets handeln Server täglich Millionen oder sogar Milliarden dieser Anfragen.Diese unerbittliche Nachfrage drängt Server, mit oder über ihre volle Kapazität hinaus zu operieren.
Überarbeiteter CPUs können bei der Prozessverarbeitung kontinuierliche, intensive Berechnungen überhitzen.In ähnlicher Weise kann der Speicher vollständig genutzt werden und Engpässe in der Datenverarbeitung erzeugen, während Festplatten ihre Speichergrenzen erreichen können, wenn sie große Datenmengen ansammeln.Wenn diese Ressourcen vollständig erschöpft sind, verschlechtert sich die Leistung des Servers und führt zu einer langsameren Verarbeitung, Systemverzögern und letztendlich aus dem Fehler.Effizientes Ressourcenmanagement ist entscheidend, um diesen Zyklus von Überlastung und Erschöpfung zu verhindern.
Plötzliche Verkehrsschwankungen
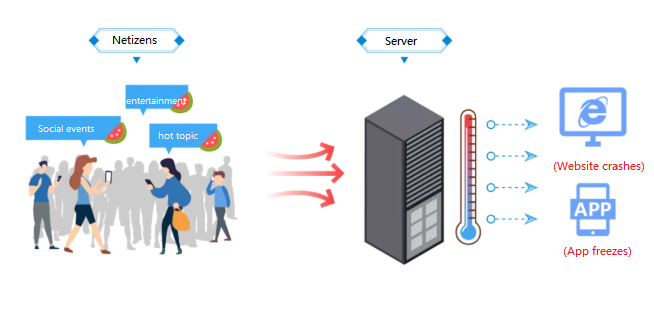
Abbildung 6. Einbruch der Benutzeraktivität
Unerwartete Spitzen im Verkehr treten häufig aufgrund viraler Inhalte, brichtlicher Nachrichten oder großen gesellschaftlichen Ereignissen auf.Diese plötzlichen Anstände erzeugen eine Flut von Anfragen, die selbst gut vorbereitete Server überwältigen können.Der mit einem digitalen Tsunami vergleichbare Zustrom übt in einem sehr kurzen Zeitraum einen immensen Druck auf die Serverinfrastruktur aus.
Selbst große Rechenzentren, die für eine hohe Nachfrage konzipiert sind, können während dieser Umstände vorübergehende Ausfälle oder Zugänglichkeitsprobleme ausgesetzt sein.Dies ist besonders häufig bei hochkarätigen Veranstaltungen wie Produkteinführungen, Ticketverkäufen oder weit verbreiteten viralen Stellen.Die Behandlung solcher Spikes erfordert skalierbare Infrastruktur- und dynamische Strategien zur Allokation von Ressourcen, um die Nachfrage in Spitzenmomenten auszugleichen.
Unvorhersehbare und unvorhergesehene Faktoren
Abbildung 7. Schrodinger Grund
Einige Serverabstürze werden durch völlig unerwartete Probleme verursacht, die häufig als "Schrodinger -Gründe" bezeichnet werden.Diese Vorfälle sind schwer vorherzusagen und erfordern häufig eingehende Untersuchungen, um zu identifizieren und zu lösen.Beispiele für solche Faktoren sind:
• Ein einzelner Fehler im Code, der einen kritischen Fehler in den Operationen verursacht.
• Zufällige Schäden an faseroptischen Kabeln während des Straßenbaus und Trennung der Konnektivität.
• DDOs (Distributed Denial of Service) greift an, die Server mit böswilligen Verkehr und überwältigenden Ressourcen bombardieren.
• Anspruchsvolle Cyberangriffe wie Trojaner -Pferdeprogramme, die Serveroperationen infiltrieren und gefährden.
• Backend -Fehler wie 5xx HTTP -Statuscodes, die Missverständnisse oder interne Fehler enthüllen.
Diese unvorhersehbaren Faktoren unterstreichen den komplizierten Charakter der Serververwaltung.Jeder Vorfall unterstreicht die Notwendigkeit von robusten Überwachungssystemen, umfassenden Tests und schnellen Protokollen zur Minderung der Auswirkungen solcher Ereignisse.
Wie verhindern Sie Serverabstürze?
Die Verhinderung von Serverabstürzen erfordert eine proaktive Strategie, die Wartung, robuste Sicherheit und ständige Überwachung kombiniert.Jeder Aspekt spielt eine entscheidende Rolle bei der reibungslosen Funktionsweise des Servers und vermeidet kostspielige Störungen.
Regelmäßige Updates
Die Aufrechterhaltung von Serverhardware und Software ist für die Aufrechterhaltung der Zuverlässigkeit und Leistung unerlässlich.Veraltete Hardware kann Schwierigkeiten haben, moderne Anforderungen zu erfüllen, während die unpatchierte Software Schwachstellen lässt, die einer Ausbeutung ausgesetzt sind.Bei regelmäßigen Hardware -Bewertungen können IT -Teams Komponenten identifizieren, die sich dem Ende ihres Lebenszyklus nähern, wie z. B. Alterung von CPUs, Speicher oder Festplatten, und sie durch effizientere Modelle ersetzen.Software -Updates, insbesondere diejenigen, die sich mit kritischen Sicherheitsfehler befassen, sollten unverzüglich bereitgestellt werden.Das Testen dieser Aktualisierungen in einer kontrollierten Umgebung verringert das Risiko von Kompatibilitätsproblemen oder unbeabsichtigten Ausfallzeiten in Produktionssystemen.
Zuverlässige Sicherungssysteme
Ein robustes Backup -System schützt vor Datenverlust und sorgt für die Geschäftskontinuität bei Ausfällen.Automatisierte Sicherungslösungen mit der Versionierung sind besonders effektiv, da sie inkrementelle Änderungen erfassen und das Risiko des Verlusts wichtiger Informationen minimieren.Das Speichern von Backups in sicheren, geografisch unterschiedlichen Standorten oder die Nutzung von Cloud-basierter Redundanz verbessert die Belastbarkeit gegen lokalisierte Fehler oder Katastrophen.Es ist gleichermaßen wichtig, den Restaurierungsprozess regelmäßig zu testen, um zu bestätigen, dass die Sicherungen zugänglich und funktionsfähig sind.Für High-Priority-Systeme ermöglichen abgestufte Backup-Strategien eine schnelle Genesung und verringern die Ausfallzeiten in kritischen Szenarien.
Temperaturüberwachung
Die Überwachung der Servertemperaturen ist entscheidend, um Abstürze zu verhindern, die durch Überhitzung verursacht werden, was zu Hardwareschäden oder Instabilität führen kann.In Server-Racks installierte fortschrittliche Temperatursensoren liefern Echtzeitdaten und helfen IT-Teams, Hotspots zu identifizieren und einen ordnungsgemäßen Luftstrom sicherzustellen.Die routinemäßige Reinigung von Ventilatoren, Filtern und Lüftungsschlitzen ist wichtig, um eine optimale Kühlungseffizienz aufrechtzuerhalten und Staubanbau zu verhindern.Die Implementierung automatisierter Kühlsysteme, die sich an die Workload -Intensität anpassen, hilft außerdem, die Betriebstemperaturen zu stabilisieren, die Lebensdauer von Serverkomponenten zu erweitern und eine konsistente Leistung zu gewährleisten.
Stresstest
Die Stressprüfung bewertet die Fähigkeit des Servers, Spitzenlasten zu bewältigen, und identifiziert Schwachstellen, bevor sie zu Fehlern führen.Die Simulation der tatsächlichen Bedingungen wie hohem Verkehr oder ressourcenintensive Verarbeitungsaufgaben hilft Unternehmen, die Grenzen ihres Servers zu verstehen.Tools wie Apache JMeter oder Loadrunner ermöglichen es IT -Teams, wichtige Metriken wie CPU -Nutzung, Speicherzuweisung und Netzwerkdurchsatz zu überwachen.Bei der Bekämpfung von Engpässen, die während des Tests aufgedeckt wurden - wie die Optimierung von Workflows, die Neuverflaltung von Ressourcen oder das Auflösen von Speicherlecks - ist der Server bereit, anspruchsvolle Szenarien zu verarbeiten.
Umfassende Überwachungssysteme
Echtzeit-Überwachungssysteme sind für die frühzeitige Aufrechterhaltung der Servergesundheit und die frühzeitige Erkennung von Problemen unerlässlich.Plattformen wie Nagios, Zabbix oder Solarwinds bieten detaillierte Einblicke in die Nutzung von Ressourcen, Leistungsmetriken und Sicherheitsereignisse.Automatische Warnungen für Anomalien wie übermäßige CPU -Nutzung oder ungewöhnliche Anmeldesversuche ermöglichen eine schnelle Intervention und verhindern, dass kleinere Probleme eskalieren.Zentrale Dashboards bieten IT -Teams eine einheitliche Sicht auf mehrere Server und ermöglichen ein effizientes Management.Regelmäßige Überwachungskonfigurationen stellen sicher, dass sie effektiv bleiben, wenn sich die Systeme weiterentwickeln und die Workloads zunehmen.
Eigenschaften von Servern
Die Leistung und Funktionalität eines Servers wird mit der Rasum -Metrik bewertet, die für Zuverlässigkeit, Verfügbarkeit, Skalierbarkeit, Benutzerfreundlichkeit und Verwaltbarkeit steht.Diese fünf Merkmale stellen sicher, dass Server ihre Designziele erreichen und operative Exzellenz aufrechterhalten.Jedes dieser Funktionen spielt eine entscheidende Rolle bei der Ermöglichung von Servern, komplexe Workloads zu bewältigen und ununterbrochene Dienste zu liefern.Unten finden Sie eine eingehende Erforschung dieser Attribute.
Skalierbarkeit
Die Skalierbarkeit ist die Fähigkeit eines Servers, im Erweitern eines Unternehmens zu wachsen und sich an steigende Anforderungen anzupassen.Diese Funktion ist von entscheidender Bedeutung, um sicherzustellen, dass Server steigende Workloads bewältigen können, ohne veraltet oder überlastet zu werden.Ohne Skalierbarkeit können selbst kostengünstige Server schnell Engpässe werden, was zu operativen Ineffizienzen und finanziellen Verlusten führt.
Verfügbarkeit
Verfügbarkeit ist ein Maß für die Fähigkeit eines Servers, eine konsistente Leistung zu erzielen und auch unter starken Workloads oder während der Wartung betriebsbereit zu bleiben.Server müssen ihre Hardware- und Softwarekomponenten ausgleichen, um mehrere Anwendungen und Benutzer zuverlässig zu unterstützen.Schlechte Konfigurationen, Überladung oder Hardwarefehler können die Verfügbarkeit erheblich beeinträchtigen, was zu kostspieligen Ausfallzeiten führt.
Benutzerfreundlichkeit
Die Benutzerfreundlichkeit bezieht sich auf die Fähigkeit eines Servers, über lange Zeiträume zuverlässig zu arbeiten, und arbeitet häufig rund um die Uhr, um die Netzwerkanforderungen zu erfüllen.Im Gegensatz zu PCs, die zeitweise verwendet werden, sind Server erforderlich, um Stabilität und Konnektivität ohne Unterbrechungen aufrechtzuerhalten.Dieses Merkmal ist besonders wichtig für Webhosting, Unternehmenssysteme und öffentliche Plattformen.
Verwaltbarkeit
Die Verwaltbarkeit konzentriert sich auf die Leichtigkeit, mit der Server überwacht, aufrechterhalten und störend sind.Während Server für den kontinuierlichen Betrieb gebaut werden, sind gelegentliche Fehler unvermeidlich.Eine effektive Verwaltbarkeit minimiert die Auswirkungen dieser Fehler, indem es eine schnelle Identifizierung und Auflösung von Problemen ermöglicht, wodurch die Ausfallzeit verringert und die Effizienz verbessert wird.
Abschluss
Server sind das Herz der modernen Technologie und sorgen dafür, dass unser digitales Leben reibungslos verläuft.Vom Streaming Ihrer bevorzugten Show bis zur Verarbeitung kritischer Finanztransaktionen ist ihre Zuverlässigkeit unerlässlich.Wenn sie jedoch scheitern, können die Ripple -Effekte signifikant sein.Zu verstehen, was Server sind, wie sie sich von Personalcomputern unterscheiden und welche Ursachen Unfälle haben, hilft uns, ihre Rolle noch mehr zu schätzen.Noch wichtiger ist, dass es die Notwendigkeit eines proaktiven Managements, regelmäßigen Wartung und robusten Schutzmaßnahmen unterstreicht.Wenn Sie diese Schritte unternehmen, kann Ihr Unternehmen die Systeme reibungslos verlaufen und Ausfallzeiten minimieren.Server mögen still im Hintergrund arbeiten, aber ihre Auswirkungen auf unser tägliches Leben sind alles andere als unsichtbar.Stellen wir sicher, dass sie zuverlässig, belastbar und bereit sind zu dienen.
Häufig gestellte Fragen
1. Was ist ein Serverabsturz?
Ein Serverabsturz tritt auf, wenn eine Website, eine Anwendung oder ein Betriebssystem nicht mehr funktionieren und unzugänglich werden und Vorgänge stören.Server, die Hardware und Software für die Bereitstellung von Daten und Diensten kombinieren, stoppen ihre kritischen Prozesse während eines Absturzes und beeinflussen alle abhängigen Systeme.
2. Wie repariere ich einen abgestürzten Server?
Um einen Serverabsturz zu beheben, Fehlermeldungen oder Leistungsprobleme zu beobachten, Blue Screen -Fehler zu analysieren, im abgesicherten Modus zu starten, um Probleme zu isolieren, Ereignis -Viewer -Protokolle und Geräte -Manager für Fehler zu überprüfen und sicherzustellen, dass kritische Dienste ausgeführt werden.Proaktive Maßnahmen wie regelmäßige Wartung, Echtzeitüberwachung und zuverlässige Leistungssicherung helfen bei der Verhinderung von Abstürzen.
3. Was verursacht Serverabstürze?
Serverabstürze werden häufig durch Stromausfälle durch Ausfälle oder Naturkatastrophen und Serverüberladungszugriff auf das System verursacht.Das Identifizieren und Ansprechen dieser Risiken kann dazu beitragen, die Stabilität aufrechtzuerhalten und Störungen zu verhindern.
4. Was passiert, wenn ein Server ausgefallen ist?
Serverausfallzeit führt zu unzugänglichen Diensten und frustriert Sie mit langsamen Antworten oder Ausfällen.Dies kann zu Kundenverlusten, Umsatzrückgang und dauerhaften Schäden an Reputationen führen, wodurch die Bedeutung der Minimierung von Störungen durch robustes Servermanagement hervorgehoben wird.
Verwandter Blog
-
Netzteilspannung Abkürzung: VCC VDD VEE VSS GND

2024/06/6
Im modernen elektronischen Schaltungsdesign, Verständnis der Abkürzungen der Stromversorgungsspannung (wie VCC, VDD, VEE, VSS, GND).Diese Abkürzung... -
Ein Überblick über TTL- und CMOS -ICs und wie Sie zwischen ihnen wählen

2024/04/13
In diesem Artikel werfen wir einen detaillierten Blick auf zwei wichtige elektronische Technologien, komplementäre Metaloxid-Halbleiter (CMOS) und Tr... -
Verschiedene Arten von Sicherungen und Anwendungen

2024/04/18
Sicherungen sind wesentliche Komponenten in modernen elektrischen Systemen und fungieren als entscheidende Beschützer vor Überstrom.Sie arbeiten, in... -
Verständnis des C1815 -Transistors: Pinouts, Schaltungssymbole, Anwendungsschaltungen

2023/12/20
Welche Art von Röhre ist der C1815?C1815 Triode PinoutC1815 ModellzeichnungC1815 -ParameterC1815 EigenschaftenAnwendung von C1815 Der C1815 -Transist... -
LR44 -Batterien: LR44 -Batterieäquivalente und LR44 -Batterieersatz

2024/01/24
In einem sich schnell entwickelnden technologischen Gebiet, in dem die Größe der elektronischen Geräte weiter schrumpfen und dennoch alltäglicher ... -
Grundkenntnisse über Sicherungen: Merkmale, Arbeitsprinzipien, Typen und wie man richtig auswählt

2024/04/10
Sicherungen schützen Schaltungen vor Schäden aufgrund von Überlastung oder Kurzstrecken.Dieses einfache, aber geniale Gerät basiert auf einem leic... -
Leitfaden zu Buck-, Boost- und Buck-Boost-Konverter

2023/12/21
Was ist ein Buck -Konverter?Wie funktioniert ein Buck Converter?Was ist ein Boost -Konverter?Wie funktioniert ein Boost -Konverter?Was ist ein Auftrie... -
Gesamtzahl der Transistoren in einer CPU
2024/06/14
In der modernen Computertechnologie ist die Beziehung zwischen der zentralen Verarbeitungseinheit (CPU) und den Transistoren zunehmend integraler gewo... -
Beschreiben Sie kurz die Spezifikationen, Verpackungen, das Arbeitsprinzip, die Vorteile und die Umweltauswirkungen von Lithium-Ionen-Batterien

2024/03/20
Seit der Einführung von wiederaufladbaren Blei-Säure-Batterien im Jahr 1859 wurden sie allmählich in den Gewebe des technologischen Fortschritts ei... -
Grunde elektronische Grundkomponenten verstehen - Widerstände, Kondensatoren, Dioden, Transistoren, Induktoren und digitale Logik -Tore

2024/04/13
Elektronische Komponenten sind der Eckpfeiler des Bauens und der Optimierung elektronischer Schaltkreise.Von gewöhnlichen Haushaltsgeräten bis hin z... -
Beherrschen analoge und digitale Schaltungen: Ein Anfängerführer

2023/12/20
Definition und Eigenschaften von analogen Schaltungen und digitalen SchaltungenDer Unterschied zwischen analogen Schaltungen und digitalen Schaltungen... -
Transistor (BJT und MOSFET) Arbeitsprinzipien

2023/12/20
Arbeitsprinzip des bipolaren Junction -Transistors (BJT)Auswahl der KomponentenwerteWie wählen Sie einen Transistor?Arbeitsprinzip von MOSFETWie scha... -
Eine vollständige Liste von Testmethoden für verschiedene Transistoren

2023/12/20
Der Transistor wurde von John Bardeen, William Shockley und Walter Brattain erfunden.Es handelt sich um ein Kollektor-, Emitter- und Basis-Drei-termin...
Heiße Teile
- GRM0335C1H7R6DA01D
- 0805YA120KAT2A
- 08052A820JAT2A
- 2225SC223KAT9A
- TAJT334M050RNJ
- MJD50T4G
- CM100DUS-12F
- IDT2309-1HPG
- ST10R172LT6
- LF442CN
- MM74HCT14M
- VNS1NV04PTR-E
- LM81BIMT-3/NOPB
- LX7178-01CSP-TR
- LM1085IS-3.3
- MCF51AC256ACFUE
- MPC850DSLZQ50BU
- TLV2322IPW
- CY7C1041CV33-20ZSXE
- UC3825ADWTRG4
- HCPL-0370-000E
- TMS320F28377DPTPQ
- ISO1H801G
- RC0402FR-0712KL
- RT0402BRD0722RL
- ATMXT768E-CU
- PIC18F67J94-I/PT
- NCV7720DQR2G
- 6MB50L-120ELX
- V24C48M100AL
- VI-910526
- AD1981AJST
- IMISC671DYBD
- AD80056KCP
- ST-L1105
- NCE8580
- AD9750ARU
- CY284010C
- MAX3232ECUE
- UPD75P068GB-3B4
- OM6361EL2.518
- T491D476K010AH4838
- DMP3018SFV-7
- MB8431-12L
- TW8825LA1-CR
- UPD65946F1-Y07-ENQ-A
- PIC33EP512MU810T-I/PT
- 2225HC392MAT3A

